2026 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2026)
Alvaro Gonzalez-Jimenez*,1,3 · Fabian Gröger*,1,2 · Linda Wermelinger1,2 · Andrin Bürli4 · Iason Kastanis4 · Simone Lionetti1 · Marc Pouly1
*Equal contribution
1Lucerne University of Applied Sciences and Arts ·
2University of Basel
3University Hospital of Basel
4CSEM
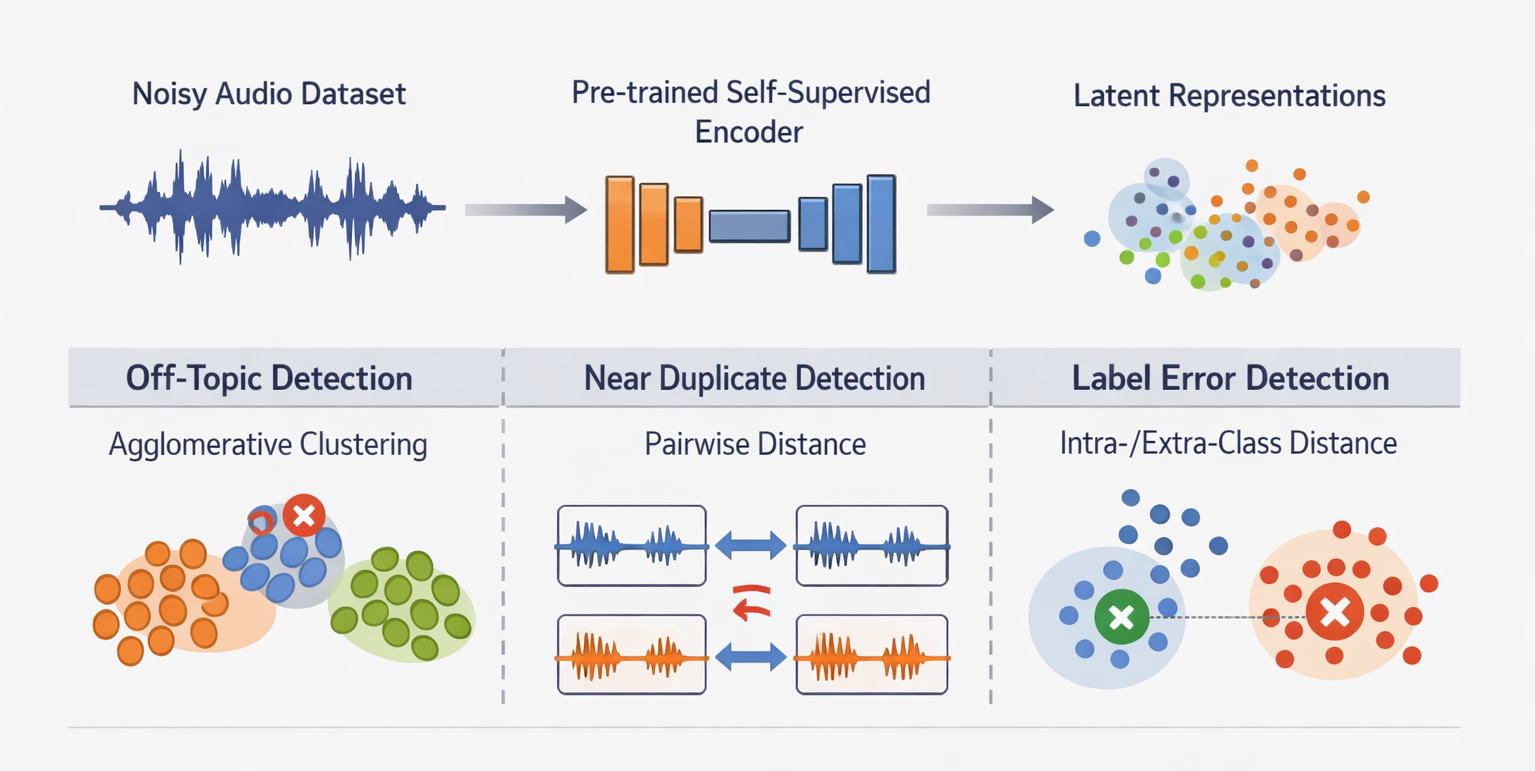
Unified audit targets
OT · ND · LE
Off-Topic, Near-Duplicates, Label Errors
Backbones evaluated
BEATs · M2D · EAT
Strong “out-of-the-box” embeddings
Operational benefit
Up to 34×
Annotation review speed-up (ND, α=0.05)
Data quality issues such as off-topic samples, near duplicates, and label errors often limit the performance of audio-based systems. This paper addresses these issues by adapting SelfClean, a representation-to-rank data auditing framework, from the image to the audio domain. The approach leverages self-supervised audio representations to identify common data quality issues and produce ranked review lists within a single unified process. We benchmark the method on ESC-50, GTZAN, and a proprietary industrial dataset, using both synthetic and naturally occurring corruptions. Results show state-of-the-art ranking performance, often outperforming issue-specific baselines, and enabling significant annotation savings by efficiently guiding human review.
Synthetic evaluation on ESC-50 under three corruption rates (α ∈ {0.05, 0.1, 0.2}). Below are the paper tables reporting ranking performance (AUROC, AP) for off-topic (OT), near-duplicate (ND), and label-error (LE) detection.
Performance of different audio embeddings for detecting OT / ND / LE across contamination rates.
| Issue | Model | α=0.05 AUROC | α=0.05 AP | α=0.1 AUROC | α=0.1 AP | α=0.2 AUROC | α=0.2 AP |
|---|---|---|---|---|---|---|---|
| OT | CLMR | 0.506 | 0.050 | 0.502 | 0.098 | 0.497 | 0.196 |
| OT | CAV-MAE | 0.309 | 0.049 | 0.260 | 0.075 | 0.273 | 0.161 |
| OT | M2D | 0.689 | 0.074 | 0.510 | 0.095 | 0.373 | 0.159 |
| OT | EAT | 0.591 | 0.070 | 0.596 | 0.138 | 0.544 | 0.222 |
| OT | BEATs | 0.766 | 0.253 | 0.745 | 0.316 | 0.673 | 0.341 |
| OT | CLMR (SSL) | 0.222 | 0.031 | 0.175 | 0.058 | 0.163 | 0.118 |
| OT | BEATs (LoRA) | 0.724 | 0.202 | 0.743 | 0.330 | 0.653 | 0.313 |
| ND | CLMR | 0.740 | 0.001 | 0.747 | 0.001 | 0.744 | 0.001 |
| ND | CAV-MAE | 0.744 | 0.032 | 0.724 | 0.017 | 0.730 | 0.018 |
| ND | M2D | 0.992 | 0.606 | 0.993 | 0.587 | 0.993 | 0.617 |
| ND | EAT | 0.930 | 0.482 | 0.922 | 0.468 | 0.931 | 0.476 |
| ND | BEATs | 0.972 | 0.606 | 0.978 | 0.595 | 0.978 | 0.625 |
| ND | CLMR (SSL) | 0.911 | 0.400 | 0.888 | 0.393 | 0.898 | 0.384 |
| ND | BEATs (LoRA) | 0.970 | 0.608 | 0.975 | 0.588 | 0.977 | 0.619 |
| LE | CLMR | 0.477 | 0.049 | 0.484 | 0.094 | 0.492 | 0.197 |
| LE | CAV-MAE | 0.721 | 0.222 | 0.693 | 0.299 | 0.658 | 0.387 |
| LE | M2D | 0.998 | 0.970 | 0.995 | 0.950 | 0.986 | 0.943 |
| LE | EAT | 0.969 | 0.668 | 0.969 | 0.759 | 0.954 | 0.793 |
| LE | BEATs | 0.996 | 0.927 | 0.992 | 0.908 | 0.980 | 0.903 |
| LE | CLMR (SSL) | 0.957 | 0.586 | 0.959 | 0.723 | 0.942 | 0.792 |
| LE | BEATs (LoRA) | 0.997 | 0.932 | 0.992 | 0.915 | 0.978 | 0.903 |
SelfClean (with BEATs embeddings) compared against Isolation Forest (OT), Dejavu fingerprinting (ND), and Confident Learning (LE).
| Issue | Model | α=0.05 AUROC | α=0.05 AP | α=0.1 AUROC | α=0.1 AP | α=0.2 AUROC | α=0.2 AP |
|---|---|---|---|---|---|---|---|
| OT | IForest | 0.791 | 0.212 | 0.676 | 0.177 | 0.406 | 0.188 |
| OT | SelfClean | 0.766 | 0.253 | 0.745 | 0.316 | 0.673 | 0.341 |
| ND | Dejavu | 0.862 | 0.017 | 0.835 | 0.033 | 0.845 | 0.068 |
| ND | SelfClean | 0.972 | 0.606 | 0.978 | 0.595 | 0.978 | 0.625 |
| LE | CLearning | 0.994 | 0.884 | 0.994 | 0.951 | 0.993 | 0.973 |
| LE | SelfClean | 0.996 | 0.927 | 0.992 | 0.908 | 0.980 | 0.903 |
Tip: on mobile, swipe horizontally to view full tables.
@article{gonzalezjimenez2025representation,
title = {Representation-Based Data Quality Audits for Audio},
author = {Gonzalez-Jimenez, Alvaro and Gr{\"o}ger, Fabian and Wermelinger, Linda and B{\"u}rli, Andrin and Kastanis, Iason and Lionetti, Simone and Pouly, Marc},
journal = {IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP)},
year = {2026}
}